Packet 07
Vectors III: Orthogonality
Subspaces of are extremely important. For example, if represents the number of pixels in an image, a vector might represent an image. The number is very large, and even computers can take a (relatively) long time to perform operations on vectors in such as multiplying matrices to compose linear transformations.
Frequently a given dataset will belong (or ‘nearly’ belong) to a subspace of of much smaller dimension. It is very useful to be able to describe and work with vectors in such a subspace in an efficient way. This typically means finding a good basis. A good basis should be easy to work with, and it should have a useful interpretation.
Orthogonal bases
An orthogonal basis is simply a basis in which the vectors are pairwise perpendicular, meaning for . It is very easy to tell if a basis is orthogonal: just compute all pairwise dot products. This is a central reason that orthogonal bases are very popular.
If a basis is orthogonal, there is a very fast way to find the components of any given vector in this basis. Suppose , meaning is a vector in the subspace of . Suppose that is -dimensional with orthogonal basis . The components of in this basis are by definition the unique coefficients in the linear combination:
Now, take the dot product of both sides with , for any given , using the fact that unless :
so
Summarizing:
Finding components in an orthogonal basis
Given an orthogonal basis, the components of are given by the formulas:
If is not only orthogonal but also orthonormal, then the components are even simpler:
The fact that components are so easy to calculate for orthogonal bases is one of their most important features, and frequently is the main reason they are used.
Question 07-01
Orthogonal vectors, finding components
Show that the set of vectors is orthogonal:
and then compute the components of in the basis .
The above method can be written out succinctly in what is sometimes called the Fourier expansion formula:
A simple observation shows another advantage of orthogonal sets of vectors – that they are automatically independent:
Orthogonal vectors are automatically independent
Suppose that is an orthogonal set.
Assume hypothetically that .
By dotting both sides with any , we see that , so we must have (because since we assume ). This can be done for any , so in fact for all .
Therefore is an independent set of vectors.
Projection
Projection and orthogonal bases Recall the projection formula:
So is just the scalar coefficient of the projection of onto (sometimes called the ‘scalar projection’).
Using this fact, we could equally write a vector as a decomposition according to an orthogonal basis using a sum of projections to the basis elements:
Projection to a subspace The projection formula for provides the closest vector to that is on the line spanned by , and the difference is perpendicular to . Furthermore, does not depend on the length of at all, in fact it only depends on the subspace spanned by , which is a line. Therefore, could really be called where is the subspace spanned by .
It is extremely useful to be able to compute the projection of a vector onto any subspace . This result should be the unique vector inside which is closest to . It is also the unique vector such that the displacement is perpendicular to (meaning: perpendicular to every vector in ).
Now suppose that we have an orthogonal basis of . We can define the projection of onto the subspace in terms of this basis:
Projection of to a subspace
-
Notice that is a linear combination of basis vectors. (Consider the separate formulas for .) Therefore it lies inside the subspace . We might have though, because here we do not assume that .
-
In addition, using this formula we can deduce that the displacement vector is perpendicular to every vector in : Consider the dot product against any basis vector :
So for all . Any element of can be written as a linear combination of the basis vectors , so is perpendicular to any vector in .
Question 07-02
Perpendicularity to a subspace
Explain and justify in more detail the last statement: “ for all ” implies “ for all .”
To summarize, orthogonal bases allow us to:
- Easily calculate the components of any vector in the orthogonal basis
- Formulate the projection of any vector onto a subspace using an orthogonal basis of the subspace
Gram-Schmidt process
In this section, we learn a procedure to create an orthogonal basis of a given subspace, starting only with some vectors that are known to generate the subspace as their span. If the original vectors are not independent, we will discover that fact along the way, and possibly wind up with a smaller number of vectors.
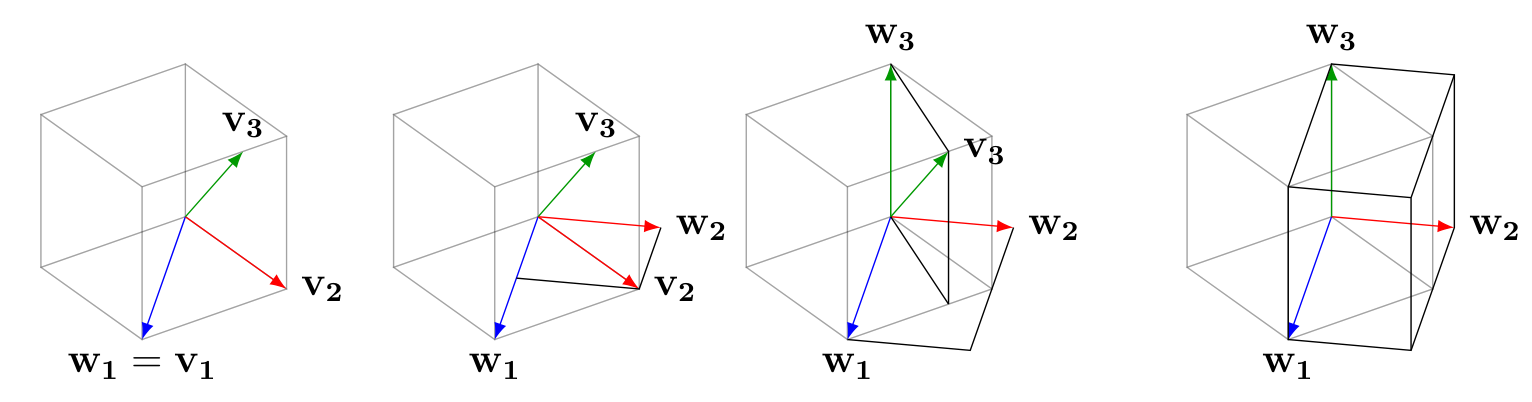 Let us illustrate the process with a span of three vectors . We do not assume they are independent.
Let us illustrate the process with a span of three vectors . We do not assume they are independent.
- Write .
- Exchange for . Since is a linear combination of and , and is a linear combination of and , we know . Furthermore, and are orthogonal.
- Now exchange for , where . Since is a linear combination of and items in , we know , and is orthogonal to everything in .
We conclude with , where the unless . So these vectors are orthogonal.
Question 07-03
Dependence?
What happens in the above Gram-Schmidt process if is a dependent set?
Example
Gram-Schmidt illustration for 3 vectors
Problem: Use the Gram-Schmidt process to find an orthogonal basis for the following span:
Solution: We first define . Then compute :
and therefore . At this point we have . Since we are just trying to preserve the span, it is convenient to change the definition of to by multiplying it by . This won’t change the span, and we eliminate the fractions.
Finally compute . Since , and this is actually an orthogonal basis for , we can use the formula for that splits it into components according to the orthogonal basis:
Therefore , and we can scale this up as with and use instead . So we have an orthogonal basis:
Exercise 07-01
Gram-Schmidt practice
Perform Gram-Schmidt to find an orthogonal basis of the subspace:
General Gram-Schmidt process
The Gram-Schmidt process can be continued in the same way for more than three vectors. Here is the general rule, in the abstract, for :
- Set .
- Write .
- Set .
- First step: use .
- We know that by considering each formula .
- We know that when (orthogonality of the we are building).
- Therefore we compute using: .
- Repeat with the next step .
- Produce a new list of vectors with .
- If the original vectors were independent, then we never have for any .
- If there is some redundancy in , then at some point and .
- We can detect this and throw out any from the final list to obtain truly independent vectors , none of which is zero.
- The dimension of the space is then , then number of nonzero items we obtained.
Application: distance from point to subspace
Many applications of linear algebra involve the measure of distance from a given vector to a subspace that does not include the vector. Typically the subspace is known as the span of a list of given vectors.
Suppose and is a subspace, given as the span of the vectors .
Here is a standard solution to the problem of finding the distance from to :
- First use Gram-Schmidt to produce an orthogonal basis of . It’s possible that .
- Now compute the projection .
- The orthogonal part is a vector from straight to .
- is the distance from to .
Example
Computing distance of point to subspace
Problem: Find the closest point on the subspace given by the span
to the vector .
Solution: Label the vectors in the span , in order. Notice that they are already pairwise orthogonal, so we can skip Gram-Schmidt. Then compute :
Therefore
and the length of this vector is , which is our answer.
Basic linear regression as projection
Linear regression: projection of dependent data vector to subspace of “best fit lines”
Basic linear regression is essentially an application of the above idea. Later we will focus on the details for a more general version; here is a preview summary:
- Data is given by vectors and matching input to output by the order of components. If there are data pairs , then will have components.
- The line of best fit should have the form . We seek and , as well as the correlation coefficient which expresses how close the data is to the best fit line. It is specifically the sum of the square distances from each component, i.e. each data pair.
- The span is all vectors of the form . These vectors encode outputs of the possible fit lines evaluated at the input data .
- The best fit line is where is the closest vector to in the span .
- Convert to the orthogonal basis . Here where is the average of the components of .
- Compute .
- Define as the coefficients and .
- Therefore we have , so then , and we have found and .
- The distance determines the correlation . The absolute distance is divided by the relative length of to get a scale-invariant number. The final formula is:
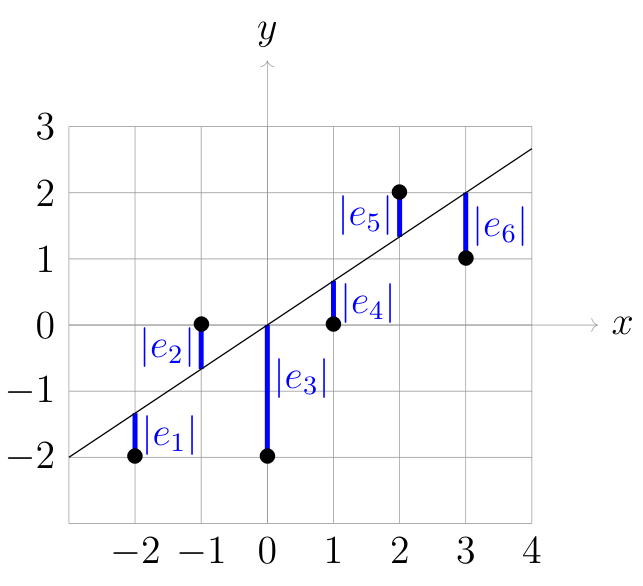
Exercise 07-02
Computing a best fit line
Following the steps above, compute the best fine line (i.e. compute and ) for the data used in Problem 05-03:
In Problem 05-03, you already found and , and implicitly and .
Derivation of correlation coefficient formula
Here we verify that
First, since , it is sufficient (confirm this for yourself!) to show that
Since and are chosen to give the closest vector to via projection, we know:
where we have used the fact that , as well as the fact that and is perpendicular to so it can be dropped from the penultimate projection. (Confirm this for yourself!)
Finally, we know that and are perpendicular. (The former lies in the span of and the latter is perpendicular to this span.) Therefore
and by plugging in we see .
Problems due Tuesday 12 Mar 2024 by 11:59pm
Problem 07-01
Gram-Schmidt calculation
Perform Gram-Schmidt to find an orthogonal basis for the span of the column vectors of the following matrix:
Problem 07-02
Distance point to plane
How far is the point from the span:
Problem 07-03
Decomposition into subspace and its complement
Suppose is a subspace. Prove that every vector can be written uniquely as a sum:
such that and is perpendicular to (i.e. perpendicular to everything in ).
(Hint: the standard way to show an item is unique is to posit two such items with the specified property, and show that they are equal to each other.)
Problem 07-04
Best fit line, nonzero averages
Find the best fit line for these five data points, and compute the correlation coefficient: