Packet 15
Application II: Principal component analysis
Raw data points are row vectors. Each entry in the row corresponds to a variable. For example .
Defining PCA
For applications to dimension reduction, this row vector could be very large: pixel grayscale values: a single row with entries.
Data matrix has row vectors that are data points. Each row is another data point. So is an vector when the data lives in and we have samples.
Sometimes , sometimes
Some authors (e.g. Wikipedia and this Packet) put data points as row vectors. Others (Lay et al., Strang) put data points as column vectors. Pay attention.
Convert raw data to mean-deviation form:
where is the average value of the entries in column of . The entries of record the displacements of the entries of from the mean across all samples (per vector component of data vectors).
Compute the sample covariance matrix:
This is a symmetric matrix. (Sized by # variables, not # samples.) The matrix is large when the row vectors are long, as for pixel data of images.
The division by comes from rule for calculating the covariance. (For more details, take a course in probability or statistics.)
The -entry of is the dot product . This dot product computes the covariance of variable and variable across the samples. The scale of this number depends on the number of samples and the relative scale of the typical variable values. After diving by , it depends only on the typical variable values.
The matrix is symmetric so the spectral theorem applies. The eigenvalues of in order, , are the principal variances of the data. The corresponding basis of (orthonormal) eigenvectors of , namely , are the principal components of the data. The square roots may be called the principal deviations, although that term is not commonly used. In our notation where data vectors are rows of , it is best to transpose the principal components into row vectors that correspond to the format of the data vectors.
Discussion
The SVD of is implicit in the above. PCA is almost directly the SVD, but there are two formatting changes to watch out for.
- may be used instead of
- Factor of appearing on the symmetric matrix
PCA ‘basically’ from SVD
PCA is derived from the SVD of (this Packet) or from (some authors).
If the data vectors are rows of and the variables are columns, then the right singular vectors of form the principal components, and singular values of this matrix form the principal variances.
If we already have the SVD, namely , then are the principal variances, and are the principal components.
For authors who write their data points as column vectors in the data matrix, the SVD of gives the PCA data: singular values are principal variances, and left singular vectors are the principal components.
Some further terminology.
Statisticians like the concept of a variable. This concept meshes with probability theory as well. The variables are represented as the quantities in the entries of the rows of the data matrix . The entries of are also the values of variables.
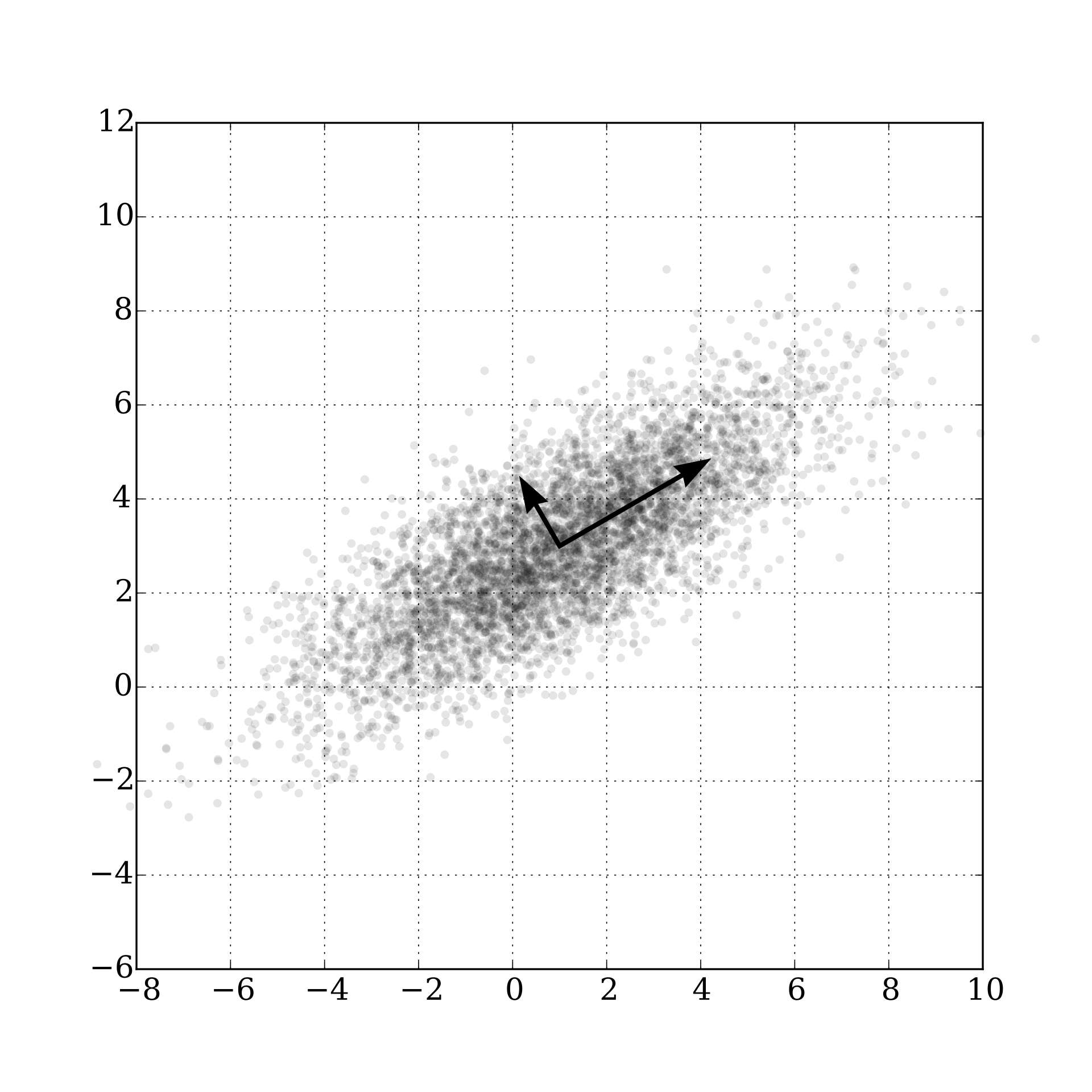
The vector is a unit vector pointing in the direction (in the data vector space) of the greatest variation in the data. The vector is a unit vector pointing in the direction (in the data vector space) of the greatest variation in the data from those directions that are orthogonal to .
Suppose we take a variable (indeterminant) input vector in the data space. Suppose . Then the dot product
gives a new variable that corresponds to the first principal component. Variables for the remaining principal components can be given as well. Collecting all variables of the principal components:
- Variance of where ranges across the data is as large as possible when the first principal component.
- Variance capture percentage: .
Applications of PCA