Stability
01 Theory - Bottleneck distance
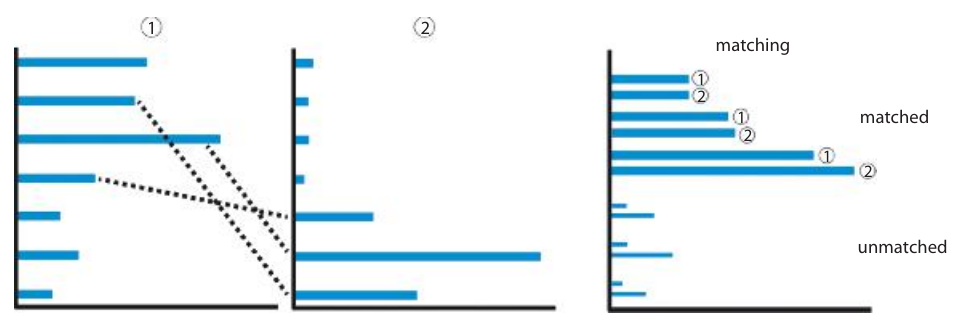
The bottleneck distance is a metric on barcode diagrams. The bars in one barcode are matched against the bars in the other. The distance between barcodes is the worst discrepancy between bars in the optimal matching.
Suppose we are given two barcode diagrams. These are two finite collections of intervals:
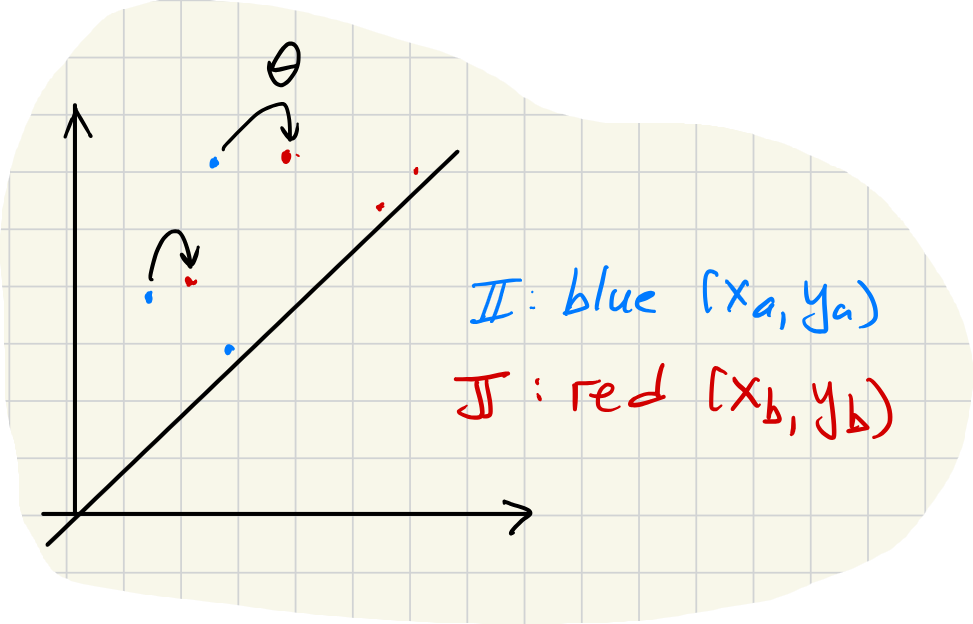
Now define the -distance between two intervals by:
Also, define:
This is the -distance to the nearest point-interval .
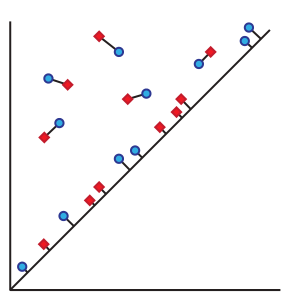
Now, suppose we are given subsets and along with a choice of bijection . Define the penalty of to be:
Bottleneck distance
The bottleneck distance from to is:
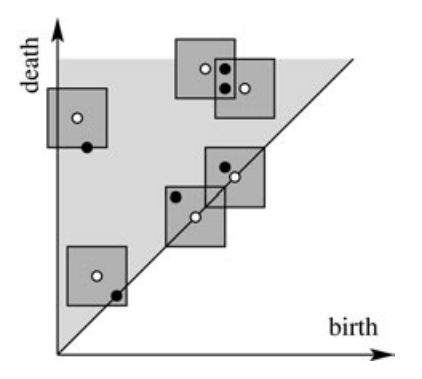
Bars far from the diagonal are matched to the closest bars (using the -norm whose unit balls are squares). Bars near the diagonal can be matched to the closest diagonal point. The distance to the closest point on the diagonal is .
Stability Theorem: Bottleneck Distance
Let and be two finite metric spaces. Fix . Let be the barcode diagram for and let be the barcode diagram for . Then:
This theorem is a kind of “stability” result regarding barcode diagrams, since it says that when two data sets and are close together (measured using the ideal, if not computable, metric ), then the barcode diagrams are also close together. Barcode diagrams cannot jump apart without the data sets jumping apart.
For example, if is a “noisy” version of , then we expect to be small, and therefore the barcode diagrams should be close. Conversely, if barcode diagrams are far, the data sets differ by “more than noise.”
02 Theory - Wasserstein metrics
The Wasserstein metrics generalize the bottleneck metric. Instead of taking the worst discrepancy between two bars in the best matching, it uses a -sum of the discrepancies of all bars in the best matching.
First define the -penalty for a partial matching as follows:
Then we minimize the penalty (find the best matching):
Remark
We can recast the -penalty in a more uniform symbolism by supplementing or with empty bars so that each has the same number of “bars,” and recalling the convention that . Then we have:
Multi-dimensional persistent homology
03 Theory - Several parameters
Thus far the persistent homology we have considered is derived from filtered spaces/complexes with a single filtration parameter :
It is possible to combine two types of filtration in a single structure having inclusion maps of each type.
Unfortunately there is no “structure theorem” for persistent homology with more than one parameter. This is basically because the structure theorem proof in one parameter involves homology with coefficients, while with parameters it involves homology with coefficients.
04 Illustration
Filtering also by density
Let us add a density filtration to . Fix and define by:
Now the points in , and the -complex itself, can be filtered by a density minimum:
This bi-filtered complex determines a 2-parameter persistence module:
For large , only points very close to distinct neighbors are included. As decreases, more points are brought in.
With data like this, the filtration (for middling values) removes points inside the disk because they are too sparse.

Filtering also by distance to a subspace
Suppose is an embedded -dimensional subspace of the background space that contains the data:.
Let measure the distance from data points to the image of .
Define . This gives a filtration in terms of the parameter . This filtration could be useful if the complete data set is too big to process all at once. The filtration allows one to process the data in layers.
These filtrations determine inclusions of complexes. For fixed and , we have:
Upon applying homology, for , we have:
And for fixed and , we have:
Upon applying homology, we have:
Finally, these induced maps should commute with each other:
05 Theory - Zig-zag persistent homology
Filtrations can be modified in another way by adding intermediate linking sets. Instead of the usual filtered space like this:
We have a “zig-zag” filtered space like this:
In general, each arrow is allowed to go either direction. The induced map on homology will follow the same pattern.
06 Illustration
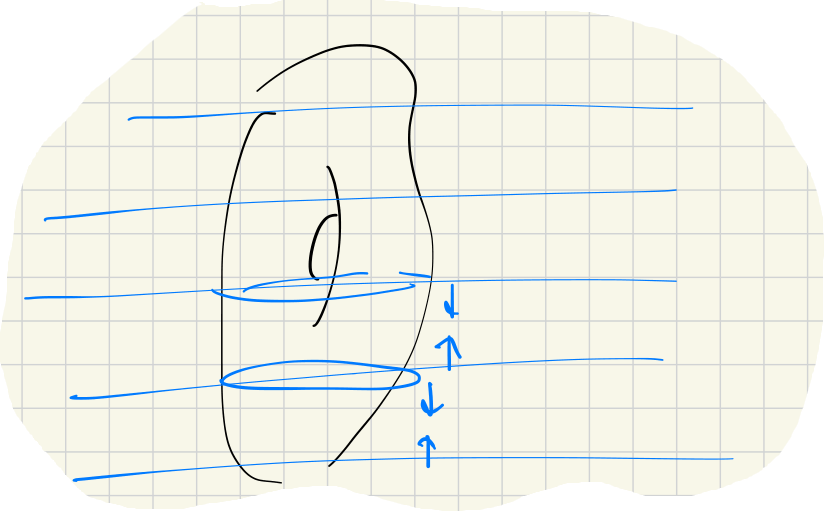
Morse layers
An application of zig-zag filtration arises by dividing the entire space into small layers for which the homology is easier to compute. For example, with a Morse function , we have this zig-zag filtration:
Repeated samples
Suppose some data is sampled repeatedly and data sets are generated in a sequence:
Then we can form a zig-zag filtration by:
Mapper algorithm
07 Theory - Clustering and Reeb graph
The mapper algorithm was introduced by Singh-Mémoli-Carlsson in 2007.
Recall the dendrogram (clustering) algorithm:
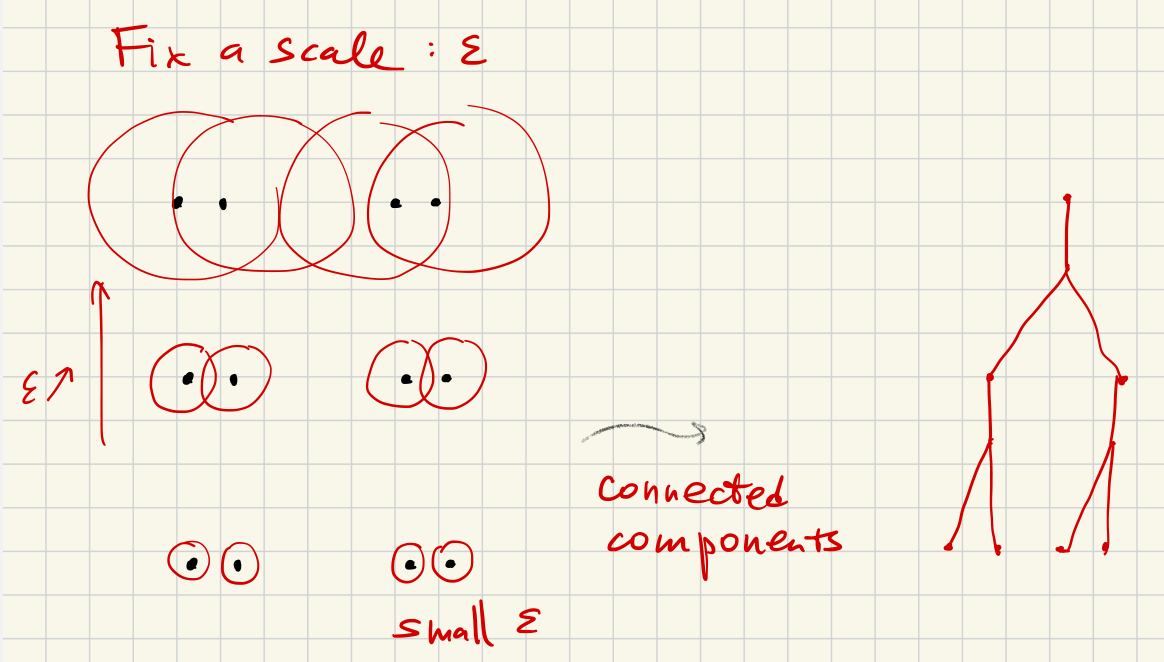
Given a fixed , two points are considered equivalent if there is a sequence of points
and the distance between successive points is much less than .
Now consider connected components (“clusters”) for each fixed . The clustering algorithm computes this and the calculation is essential the same as persistent homology for .
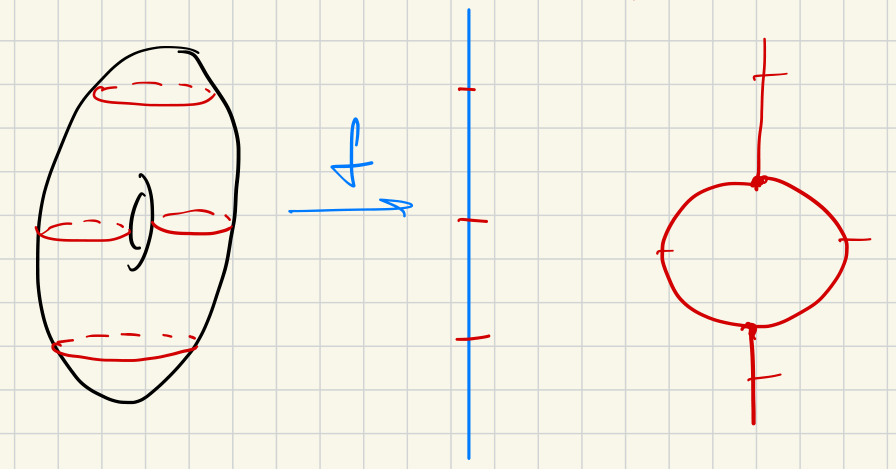
Reeb graph
Given a Morse function on a manifold , the Reeb graph is formed by the equivalence relation:
Two points are equivalent if:
- AND
- are in the same connected component of
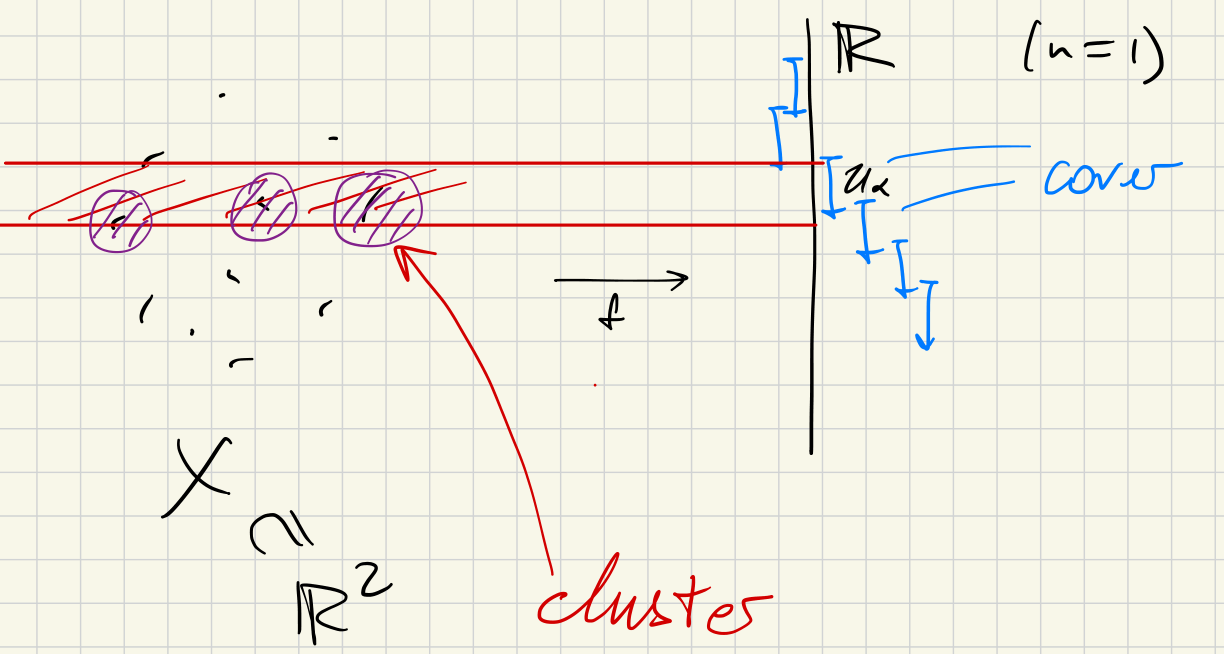
08 - Mapper algorithm
Let us be given:
- A finite metric space
- I.e. a finite collection of points with distances between them; usually
- A “filter function”
- A finite cover of in
- Typically a collection of boxes in
Proceed as follows:
(1) Consider the clustering of each :
- Choose and consider clusters at this scale .
- Write for the clusters, so
(2) Form a discrete version of the Reeb graph:
- Vertices: clusters
- Edges: when and overlap
- Color the vertices according to values of (on average):
09 Illustration
Simple cover
Suppose and suppose is just the interval containing the entire .
In this case Mapper produces a graph with no edges. Its vertices correspond to clusters of .
2-Component cover
Suppose and suppose is the pair and . Mind the gap .
Vertices in the Mapper graph are -clusters of and of . These clusters must be all disjoint. So there are no edges between the vertices.
If, however, the cover had been chosen to be and , there could be vertices between clusters in and clusters in .
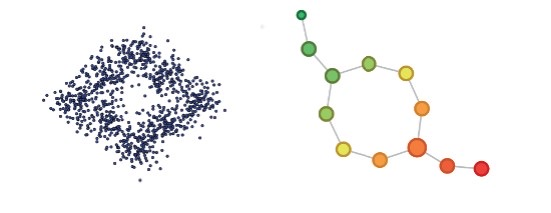
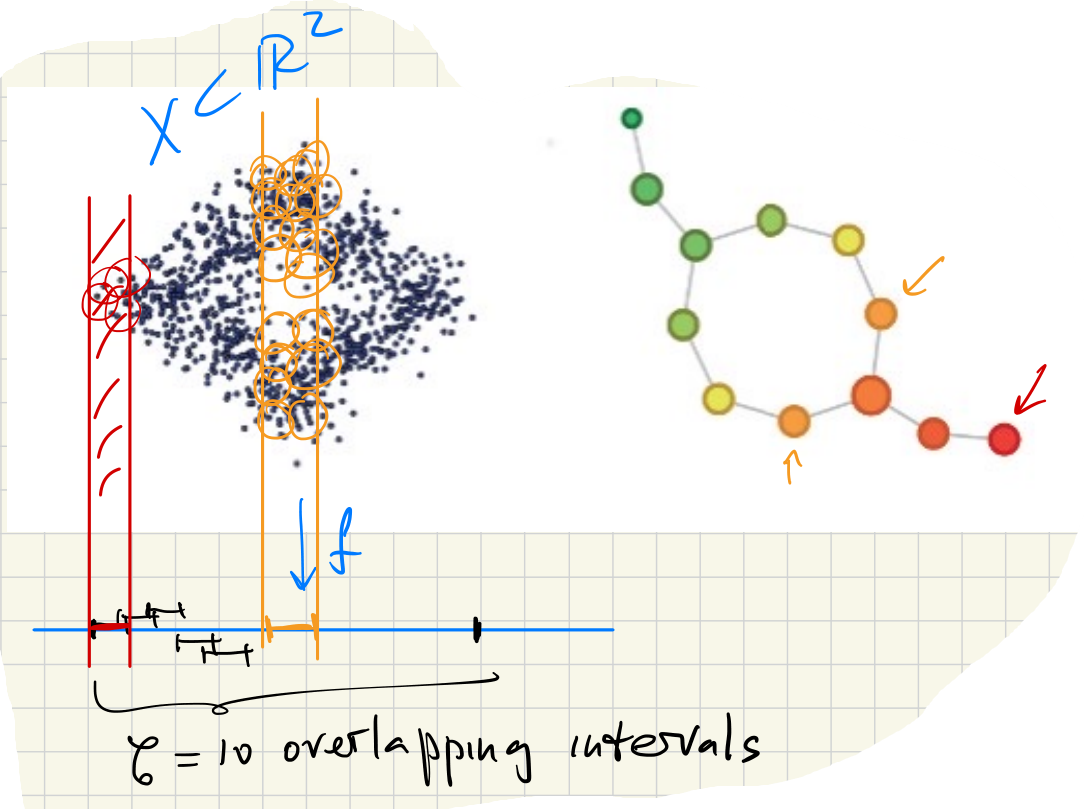
Consider data points sampled around the unit circle. Let by . Suppose the image is covered by small overlapping intervals of equal length. Mapper recovers the topology of the circle:
If we had used a simple cover (single interval), the Mapper graph would have no edges and thus would not express the circle’s topology.
(Rabadan-Blumberg 2020)
(Nikolau-Levine 2011)
Dimensionality reduction and manifold learning
These techniques work well if the given data happens to lie near a lower-dimensional vector subspace or submanifold of the original space.
Foundational algorithms are
- PCA “principle component analysis” — vector subspaces
- starts with a finite metric space (point-cloud data)
- MDS “multidimensional sampling” — manifold subspaces
- starts with arbitrary metric space
Goal:
Given (small) , find an optimal map which in some sense represents the structure of the data by minimizing the error:
10 Theory - PCA
Let be an matrix with eigenvalues and eigenvectors , so .
Recall that if is symmetric, we know that and
For PCA, we start with . Fix small.
The goal is to find an “optimal” linear map which distorts distances between data points as little as possible. (Minimal mean-square error.)
PCA Algorithm: (1) Normalization
Consider and let .
(2) Covariance matrix
Define the covariance matrix :
Note that . Then, since each summand of is symmetric, must be symmetric.
(3) Eigenvalues
Compute the top (largest) eigenvalues of .
If these are pairwise distinct, the corresponding eigenvectors are all linearly independent, so they span a -dimensional linear subspace .
Consider the orthogonal projection .
(Note: one must somehow identify with first.)
If some eigenvalue has multiplicity, then consider the corresponding eigenspace .
Theorem:
The outcome of this algorithm is an optimal which minimizes the error .
(In the context of PCA or MDS, in fact.)
Combining techniques
It is often reasonable to combine techniques discussed thus far.
For example, the outcome of PCA/MDS may be fed into Mapper; a coordinate project in the PCA output may be used as the filter function.
11 Theory - MDS
Multi-dimensional scaling starts with an arbitrary finite metric space , and attempts to embed this in in a way that is optimal in the sense of minimizing . This is done as follows:
(1) Metric matrix:
(2) and
Let be the matrix where is the matrix with all entries .
Let be the matrix .
(This step centers the result at the origin.)
(3) Define :
Create a matrix with columns the eigenvectors , normalized so that . Then:
12 Theory - Isomap manifold learning
The given data is aligned along a non-linear subspace of .
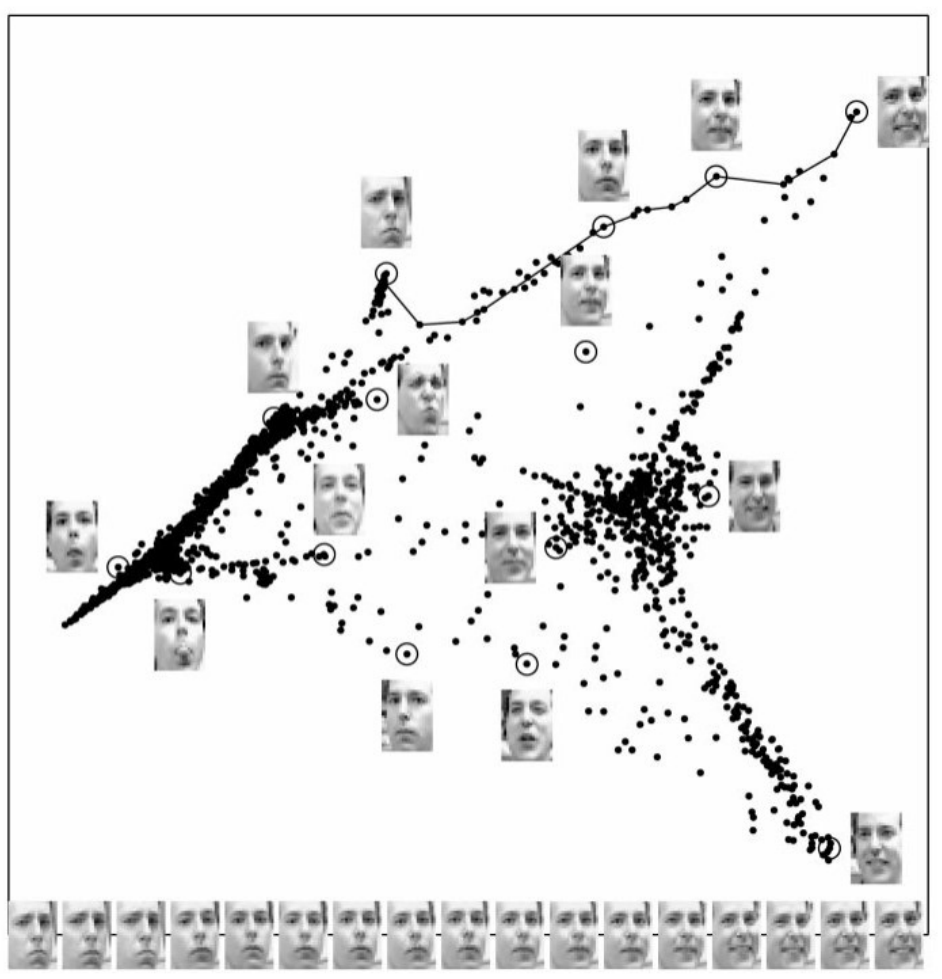
This method is used in facial recognition, for example.
We are assuming that the data lies along (very near) a submanifold . This is assumed to have an “intrinsic” metric for .
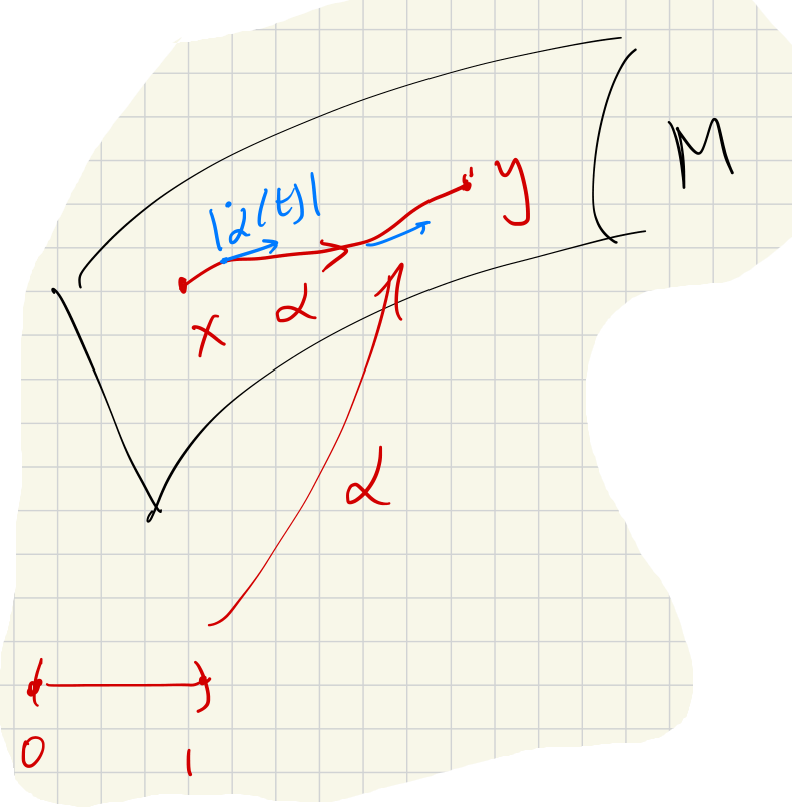
The idea of isomap is that, assuming is smoothly embedded, there is a scale at which
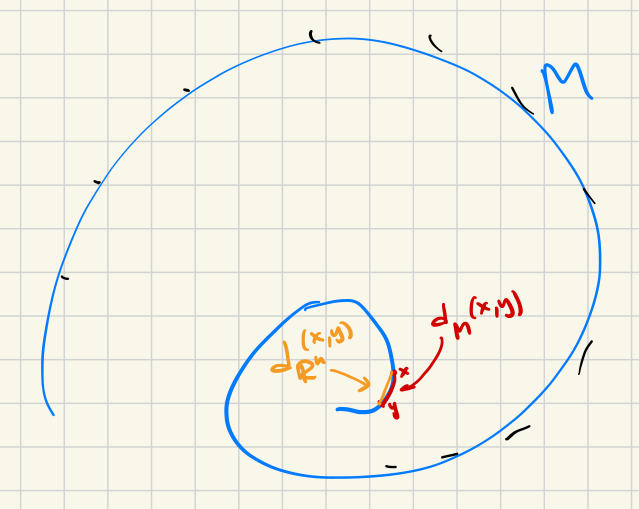
Isomap description in detail:
Let us be given , as well as a scale and a target dimension .
Isomap procedure
(1) Build weighted graph :
- Vertices: the points
- Edges: join to when
- Weights: the distances
(2) New metric space :
Same points, new distances:
(Use Dijkstra’s Algorithm to compute the minimal path.)
(3) Apply PCA/MDS:
Find an optimal map .
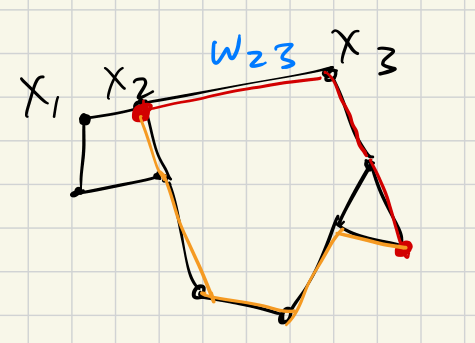
Isomap - single chart
Isomap is most effective when the manifold can be covered by a single chart and the algorithm effectively “flattens” and “unrolls” the space.
It is less effective for manifolds with topology. For example, when applied to , the output of isomap is a flat disk.
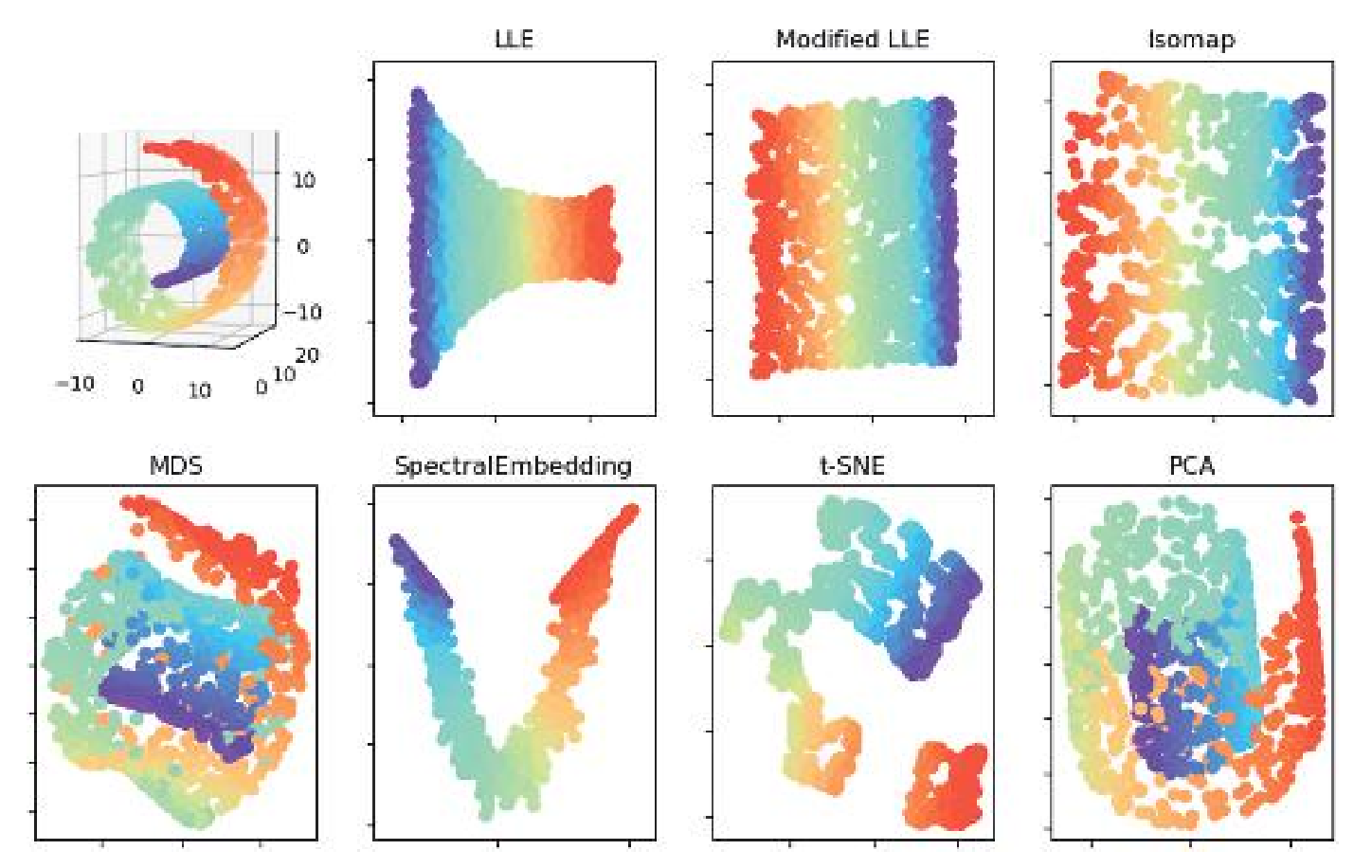
(Rabadan-Blumberg 2020)
13 Theory - Local Linear Embedding (LLE)
LLE is a variation of isomap manifold learning that is “locally linear.” It does not attempt to preserve the metric globally. The algorithm is a little more efficient than isomap as well.
LLE Procedure
Suppose we are given the data set , the target dimension and a “neighborhood size” .
(1) Find minimizer weights:
For each , find weights that minimize the error:
subject to the constraints:
The weights determine approximations of a point using the plane that best fits its neighbors. If the manifold is actually linear around a point, the error at that point will be zero.
(2) Use minimizer weights to recover points:
Find points that minimize the error:
The new embedding is .
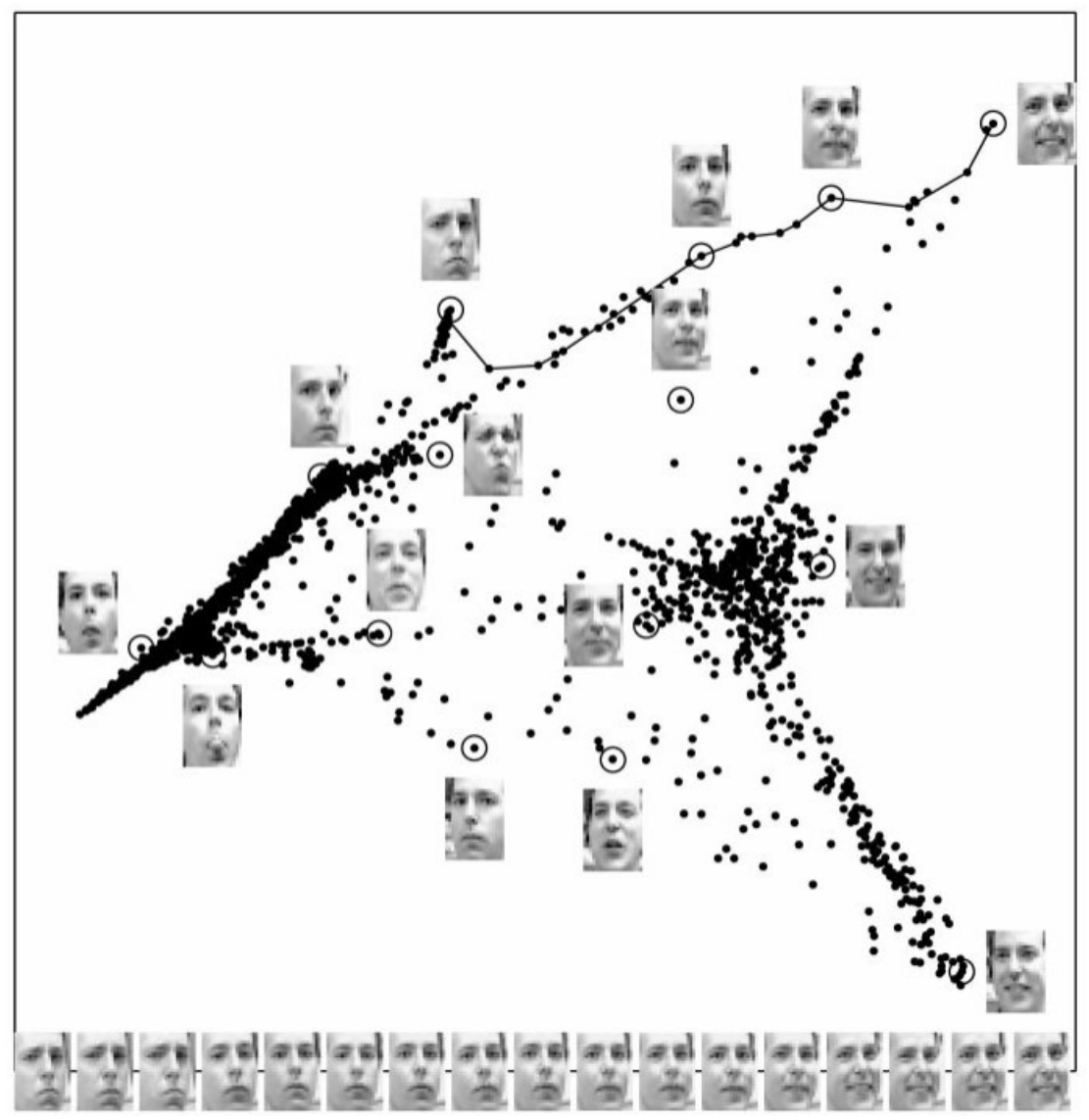
Locality
The Isomap and LLE algorithms are local, meaning that the output is determined by the data around . Data points far from have no effect on .